Db4o: una nueva alternativa a la persistencia
Introducción
En todo proyecto de software el manejo de la persistencia normalmente representa una inversión de esfuerzo muy grande lo que se traduce en un costo más elevado para nuestra aplicación.
En la actualidad, para resolver esta problemática, se utilizan herramientas de mapeo objeto-relacional (object-relational mapping) tales como Hibernate las cuales nos ofrecen una solución que dista de ser óptima cuando se trata de implementar un software específico, tal como software en tiempo real o software empotrado (ej. en PDA) o aquel que se instala en algún contexto cerrado donde se requiere una base de datos transparente.
db4objects (abreviado db4o) fue diseñado para proveer un motor embebido de base de datos orientado a objetos para dispositivos móviles, desktops o servidores donde se requiera alto desempeño, sincronización, consumo mínimo de recursos y principalmente cero administración. Se trata de una librería de código abierto (con licencia GPL y también comercial) que podemos integrar a nuestros proyectos muy fácilmente. Es nativa a los entornos donde opera (posee versiones Java, .NET y Mono) y permite realizar transacciones confiables y escalables con tan solo una línea de código sin importar lo compleja que sea la estructura de los objetos a almacenar.
Los usuarios buscan en la práctica ciertas características deseables en un motor de base de datos de este tipo: que sea pequeña, rápida, poderosa y fácil de utilizar. Esto se traduce en requerimientos de consumo de recursos mínimo (importante para dispositivos embebidos), una alta velocidad de procesamiento (nadie se queja porque las consultas sean demasiado rápidas), una implementación sencilla (con curva de aprendizaje pequeña y un corto tiempo para sentirse cómodo con la base de datos), portabilidad (no ligada a un sistema operativo específico) y confiabilidad (una base de datos no confiable es simplemente inutilizable).
Figura 1 – Diagrama de requisitos
Veamos ahora en detalle cada uno de estos requisitos:
· Consumo mínimo de recursos. A pesar de que los avances en tecnología permiten a los diseñadores de sistemas comprar más memoria a precios cada vez más bajos, la optimización del consumo de memoria de una aplicación nunca pasará de moda. El cálculo es sencillo: si nuestro motor de base de datos consume menos memoria, habrá más disponible para otros componentes de la aplicación y el diseñador podrá agregar más características (o incrementar el desempeño de las existentes).
Note que hemos usado la palabra 'optimización' arriba. No hablamos solo de reducir el tamaño de la librería de base de datos - eso puede lograrse amputando funcionalidad. Pero intercambiar funcionalidad por bytes es peligroso: uno terminará con un producto más compacto pero quizás también menos útil.
· Alto rendimiento. Este requerimiento está fuera de discusión. En muy pocas aplicaciones se toleran largos tiempos de acceso. Puesto de otra forma, no se conocen quejas de una base de datos que devuelva los resultados demasiado rápido.
· Fácil implementación. A pesar de todas las mejoras en los ambientes de desarrollo, en la programación orientada a objetos, en los frameworks con algoritmos y estructuras de datos predefinidas, los desarrolladores aun deben diseñar y codificar la lógica de negocio de la aplicación – una tarea aun difícil. Por lo tanto, la API de un motor de base de datos no debería representar un desafío al aprendizaje. Debería ser ‘lo más simple posible pero no más’, tomando prestada una expresión conocida. Esto crea una curva de aprendizaje mínima y reduce el tiempo necesario para sentirse cómodo con el uso del motor.
Adicionalmente, incorporar la funcionalidad de base de datos en un proyecto de desarrollo debería ser un proceso de un solo paso. Idealmente, la librería consistiría en un solo archivo (para Java un .JAR; para .NET un archivo .DLL). Para proyectos basados en línea de comandos, agregar el motor debería tratarse de modificar una sola línea en un script de construcción (build); para proyectos basados en un IDE, el agregado debería tratarse de una operación de arrastrar y soltar.
· Portabilidad. Un motor de base de datos debería ser multiplataforma para maximizar las ubicaciones donde puede correr – y así incrementar los potenciales clientes de la aplicación. Una amplia portabilidad le da a los desarrolladores el lujo de programar en un S.O. importante – y así tomar ventaja de las herramientas de desarrollo y debugging de última generación – con la garantía de que el resultado no estará ligado a ese S.O.
· Confiabilidad. La confiabilidad es otro requerimiento indiscutible – y probablemente el más importante. Una base de datos no confiable es simplemente inutilizable. Para la mayoría de las aplicaciones empotradas, en especial las empleadas en sistemas de tiempo real, la confiabilidad es una propiedad no negociable que deben tener TODOS los componentes.
Más aun, el motor de base de datos debe desempeñarse de acuerdo a criterios reconocidos de la industria. Específicamente, la librería debe implementar las propiedades ACID.
La solución: db4o
db4o es un motor de base de objetos que permite cubrir (y exceder) los requerimientos antes mencionados. Veámosla punto por punto:
· Consumo mínimo de recursos. db4o está diseñado para ser embebido en clientes u otros componentes de software de forma totalmente invisible para el usuario final. Es por ello que db4o no necesita un proceso de instalación por separado sino que viene como una librería que es de fácil incorporación con un footprint que ronda los 400Kb. Como db4o corre en el mismo proceso de la aplicación, el usuario cuenta con control completo sobre la administración de memoria y puede realizar procesos de profiling y debugging del desempeño sobre todo el sistema. Si la aplicación está corriendo la base también, sin excepción.
Y aun más importante, db4o es extremadamente flexible a la hora de actualizar una base existente con un modelo de objetos que ha cambiado. db4o siempre asume que no hay un administrador de base de datos y por lo tanto permite a la aplicación cambiar del modelo viejo al modelo nuevo de forma transparente. A diferencia de otras soluciones de bases de datos (sean relacionales o de objetos no nativas) este motor no necesita de la funcionalidad de administración de las actualizaciones del modelo de datos – una fuente de trabajo y errores de la que ya no debemos preocuparnos.
· Alto rendimiento. El rendimiento de db4o es equiparable al de los mejores sistemas de bases de datos tradicionales. Los benchmarks que se muestran a continuación en el link muestran el desempeño de db4o comparado al de una base de datos SQL corriendo en una máquina de escritorio:
http://www.db4objects.com/about/productinformation/benchmarks/
Benchmarking de db4o. La tabla muestra el desempeño de db4o comparado al de una base de datos SQL de escritorio para un conjunto de operaciones representativas de lectura (select) e inserción. No solo db4o presenta buenos resultados comparativos sino que en algunos tests muestra una ventaja significativa en la velocidad con respecto a la competencia.
· Fácil implementación. Sólo agregue la libraría única de db4o (.jar o .dll) a su entorno de desarrollo, abra el archivo de base de datos y almacene cualquier objeto (sin importar su complejidad) con una sola línea de código. Por ej. en Java:
public void guardar(Auto auto){
ObjectContainer db =
Db4o.openFile("auto.yap");
db.set(auto);
db.commit();
db.close();
}
Está facilidad de uso sin precedentes se traduce en una reducción drástica de los tiempos de desarrollo.
Se elimina efectivamente todo el trabajo de diseñar, implementar y mantener el esquema de base de datos ya que el propio modelo de clases conforma este esquema. Y ya no se necesita administrar tareas relacionadas a la base de datos como strings, archivos XML u otros archivos no nativos que requieren pre o post compilación lo que siempre hace más lento el proceso de producción. Todo tarda menos de 5 minutos, se ahorra mucho tiempo de desarrollo.
Pero aun se ahorra más tiempo a la hora de cambiar el software por ejemplo durante la refactorización del código, agregado de nuevas características o la reutilización de componentes de software. Por ejemplo, el cambiar el modelo de objetos no solo es extremadamente transparente sino que también es a prueba de errores ya que la naturaleza nativa y no intrusiva de db4o permite que el ambiente de desarrollo haga todo el trabajo. No se necesitan debuggers, procesos de compilación y no es necesario preocuparse por las bases ya instaladas ya que el motor se encarga de soportar cualquier modificación del modelo de objetos sobre las bases ya existentes. En lo que se refiere a la persistencia el cambiar el software deja de ser una pesadilla y se convierte en un placer lo que aumenta la productividad.
En definitiva, db4o hace igual fácil el persistir objetos que un proceso simple de serialización pero además le da un conjunto completo de funcionalidades y características de las bases de datos como la realización eficiente de consultas y el soporte a cambios en el esquema.
· Portabilidad. Pocas bases de datos embebibles corren de forma nativa en tantas plataformas orientadas a objetos como db4o (y ninguna corre en estas plataformas en ambientes heterogéneos). db4o permite desarrollar aplicaciones para despliegue en varias plataformas (ej. en PDAs) o en combinaciones heterogéneas de clientes Windows y servidores Java.
Este motor soporta desde el JDK 1.1.x de Java hasta el 5.0 y es soportado en J2EE y J2SE. También corre con dialectos de J2ME que soportan reflexión, como CDC, PersonalProfile, Symbian, Savaje y Zaurus (db4o también correrá pronto en dialectos sin reflexión como CLDC, MIDP, RIM/Blackberry y Palm OS).
db4o también es compatible con todas las plataformas .NET, el CompactFramework y Mono, soportando todos los lenguajes .NET administrados como C#, VB.NET, ASP.NET, Boo y Managed C++.
· Confiabilidad. Finalmente, db4o soporta todas las características ACID. Múltiples usuarios simultáneos de una base db4o son efectivamente aislados, sus operaciones serializadas de forma transparente por la librería. Las transacciones son terminadas por los métodos commit() y rollback() de la clase ObjectContainer. Y en caso de que el sistema se caiga durante una actualización de la base de datos, cuando el ObjectContainer de db4o sea reabierto, se completarán de forma correcta todas las transacciones interrumpidas.
La librería db4o
En este apartado vamos a presentar una breve introducción a la librería que nos provee db4o y que mejor que dar un ejemplo con los tópicos mas comunes que nos encontramos en un modelo orientado a objetos.
El ejemplo será presentado utilizando el lenguaje java, solo por comodidad, sin embargo como muchos conocemos, esto no será un problema para comprender el concepto.
Antes de comenzar deberíamos tener en cuenta las herramientas a descargar para trabajar con db4o. Las mas básicas, y que serán utilizadas en este ejemplo, son: la librería de db4o para java, actualmente en la versión 5.5 y el ObjectManager, actualmente en versión 1.8 (ver links en “información del producto” al final del articulo).
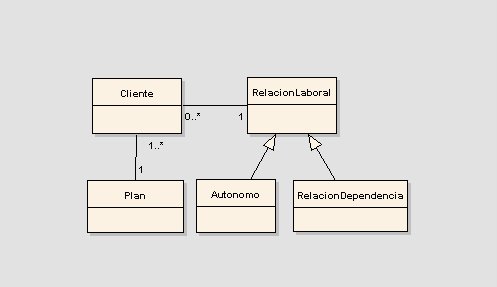
La figura 1 nos muestra el modelo que vamos a tener en cuenta durante este ejemplo, les pedimos disculpas por lo anémico que se encuentra, pero sepan comprender que solo haremos hincapié en sus datos a persistir. El modelo responde a un problema que enfrenté hace un tiempo atrás (por supuesto mucho más acotado) sobre una aplicación de planes de ahorro. La clase cliente representa el acreedor del producto y esta asociado a un plan de ahorro. En el dominio existían validaciones necesarias para agregar a un cliente a un plan de ahorro, entre ellas, la realidad fiduciaria; para administrar estos asuntos decidimos agregar una relación laboral que en base a su sueldo bruto, nos calcule su neto para evaluar si dicho cliente supera cierto umbral y dejarlo en una posición habilitada, frente a la empresa, para abonar mes a mes la cuota correspondiente.
Fig 1.

Nos dedicaremos el resto del apartado para ir al código (que seguramente mas de uno lo debe estar esperando)
Crearemos un proyecto java utilizando el editor eclipse y agregaremos las referencias a los jar correspondientes a la librería db4o 5.5.
Ahora bien, la clase principal que nos provee acceso a los servicios de db4o mediante sus métodos estáticos es el llamado ObjectContainer, a través de este, realizaremos todas las transacciones que necesitemos.
El código presentado en la figura 2 va a ser nuestro primer ejemplo en el cual nos acotaremos a persistir los objetos de relación laboral, algo así a lo que seria una tabla de “tipos de algo” en la antigua entidad relación, recuerdan? aquella donde teníamos una relación entre producto y tipo de producto, y esta ultima tabla solía ser un id-descripcion. Como podrán ver, siguiente el código con sus comentarios habla por si mismo, fácilmente a través del ObjectContainer podremos persistir las entidades del modelo.
Un punto importante a tener en cuenta es la inserción de duplicados (no alarmarse), este tema es representativo ya que recibimos muchos threads dentro del foro al respecto. Cuando uno guarda un objeto compuesto X por otros Y, hay que tener conciencia de que estos otros objetos Y deberían haberse persistido previamente (esto lo podemos observar en el primer ejemplo propuesto), al no ser asi, por mas que el objeto Y dentro del objeto X sea idéntico a otro Y ya persistido previamente, Db4o no se dará cuenta de esto y guardara toda la estructura del objeto X dejando así un duplicado del objeto Y. Por supuesto el tema no es tarea compleja y a la hora de construir este objeto X le haremos una consulta a Db4o para pedirle el objeto Y, y utilizaremos esta referencia, que ya esta siendo tomada en cuenta por Db4o.
 En el ejemplo de la figura 2, vamos a buscar el objeto Autónomo por su identificador (todavía no prestar atención a como saque el identificador del objeto guardado), este tratamiento de identificadores se encuentra manejado totalmente por Db4o a través de su extensión del object container accesible por el método ext() y por lo que no necesitaremos agregarle información extra a nuestras clases, que por supuesto, es una cualidad menos intrusiva.
En el ejemplo de la figura 2, vamos a buscar el objeto Autónomo por su identificador (todavía no prestar atención a como saque el identificador del objeto guardado), este tratamiento de identificadores se encuentra manejado totalmente por Db4o a través de su extensión del object container accesible por el método ext() y por lo que no necesitaremos agregarle información extra a nuestras clases, que por supuesto, es una cualidad menos intrusiva.
Fig 2
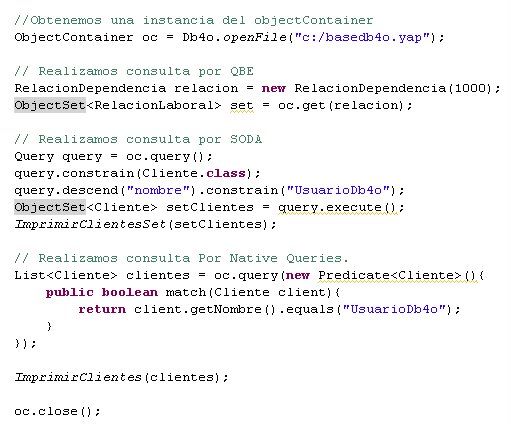
En la figura 3 presentamos los ejemplos de consultas. Db4o presenta tres métodos para realizar consultas.
El primer método es Query By example(QBE) en el cual la idea principal es darle al ObjectContainer un objeto que represente el criterio de los objetos a buscar dándonos así resultados de objetos “parecidos” al objeto que le damos
El segundo método es el llamado SODA, en el cual podremos realizar las consultas más complejas dentro de estructuras profundas a través de una clase llamada Query. Esta clase provee métodos particulares que nos permiten descender en la información de una propiedad del objeto a buscar.
El ultimo método y mas requerido por los fanáticos, es el de las Queries Nativas, donde realmente la consulta esta expuesta en el lenguaje de programación que uno desarrolla, por lo tanto son 100% type safe, 100% compile time checked y por supuesto 100% refactoreables.
En el ejemplo, por supuesto, incluimos las tres formas de consultar objetos para obtener nuestro ObjectSet lleno de objetos, pero vamos a darle una consideración especial a las queries nativas ya que esta última son la postura a tomar por cada desarrollador y ha dado una revolución dentro de db4o. El comportamiento principal que tenemos que tener en cuenta a la hora de hablar de este tipo de queries es el de performance, mucha gente en los foros se viene quejando al respecto; y déjenme comentarles, que es algo inevitable. Las queries nativas funcionan sobre SODA, por lo que cada una de ellas pasara por un conversor, lo cual incluye tiempo de procesador, y la ejecutara en formato SODA. Para mejorar estos tiempos, Db4o pensó en una herramienta llamada Native Query Optimizer la cual se encuentra actualmente en desarrollo y se encarga de configurar el contenedor para que las consultas sean lo mas optimas posible, sin embargo, una descripción de esta herramienta deberá quedar para un próximo articulo.
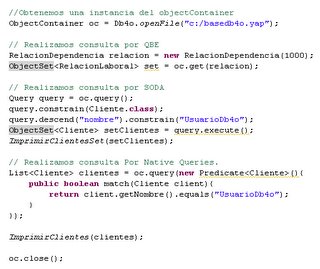
fig 3.
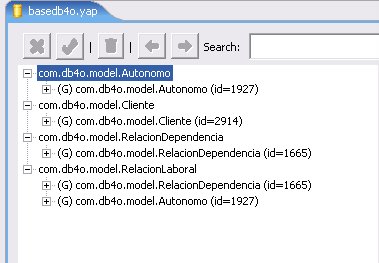
Hasta aquí podremos notar que la librería se comporta como debería, pero nos queda una sensación de vacío al no saber donde se encuentran realmente los datos. Para visualizarlos podremos utilizar la herramienta ObjectBrowse. Una vez levantada esta aplicación, levantaremos el archivo de la base utilizando file->Open File…, apuntaremos al archivo y nos mostrara algo semejante a la figura 3.
Las particularidades que podemos observar aquí es el almacenamiento de la jerarquía, donde la clase abstracta es almacenada y guarda un apuntador a los objetos concretos y la administración de los identificadores por parte del ObjectContainer.
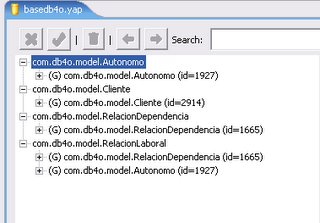
Otro tema importante para tener en cuenta es el cambio de performance a partir de la versión 5.4 (por lo que recomiendo una versión igual o mayor), donde se ha introducido una arquitectura BTree diseñada para todos los índices de db4o tales como: Class index, field index, Collections index
Conclusión
db4o es una solución de persistencia ideal para cuando se necesita una base transparente y fácil de utilizar para incorporar rápidamente a un proyecto Java o .NET sin sacrificar desempeño. Logra acortar los tiempos de entrega de nuestras aplicaciones de forma significativa ya que permite concentrarnos directamente en el dominio del problema (nuestros objetos) sin que debamos invertir demasiado tiempo en la solución de persistencia (mapeos objeto-relacionales, archivos XML, etc.). Adicionalmente, db4o ofrece características avanzadas como soporte transparente a cambios en las versiones de los objetos (evolución del esquema), cero administración (no requiere DBA), consultas nativas y, por si fuera poco, es de código abierto!
Más información
El sitio de db4o es http://www.db4o.com/. Al ser el producto de código abierto, también cuenta con un sitio que provee información y herramientas para desarrolladores:
http://developer.db4o.com/files/default.aspx
En esta dirección encontraremos diferentes secciones que abarcan:
1) Descargas, donde además de tener la posibilidad de descargar db4o y el ObjectManager, tendremos acceso a diferentes productos aportados por la comunidad, entre ellos se encuentra “db4o Integration Framework”, un framework que está siendo desarrollado por la comunidad Hispana y futuro grupo de usuarios.
2) Un foro muy activo en diferentes idiomas, donde la comunidad Hispana es la segunda mas activa (la primera es la comunidad de habla inglesa) y donde podremos encontrar todas las peculiaridades que posee db4o como producto y solución.
3) Proyectos, recursos, blogs, etc.
Espero que les haya gustado el articulo. Este articulo fue creado por Alan Lavintman y German Viscuso.
Si necesitan el fuente, no duden en consultar.
Saludos y hasta el proximo post.